Yapay Zeka Uygulamaları
3/9/2025
Tencent İki Yüksek Performanslı Çeviri Modelini Açık Kaynaklı Hale Getirdi
Çinli teknoloji devi Tencent, iki özel çeviri modelini açık kaynaklı hale getirdiğini duyurdu. Şirket, modellerin uluslararası ölçütlerde Google Translate gibi yerleşik araçlardan daha iyi performans gösterdiğini açıkladı.
WMT2025’te, yani araştırma ekiplerinin çeviri sistemlerini karşılaştırdığı büyük ölçekli çalıştayda, Tencent’in yeni modelleri Hunyuan MT 7B ve Hunyuan MT Chimera 7B, test edilen 31 dil çiftinin 30’unda en üst sıraya yerleşti. Çeviri Modelleri Çalıştayı (WMT), çeviri modellerinin değerlendirilmesinde önde gelen etkinliklerden biri olarak kabul ediliyor.
Her iki model de 33 dili çift yönlü olarak destekliyor. Bunlar arasında Çince, İngilizce ve Japonca gibi yaygın kullanılan dillerin yanı sıra Çekçe, Marathi, Estonca ve İzlandaca gibi dijital ortamlarda daha az temsil edilen diller de bulunuyor. Tencent, özellikle Mandarin Çincesi ile Çin’deki azınlık dilleri arasındaki çeviriye odaklandığını belirtiyor. Modeller, Çince ile Kazakça, Uygurca, Moğolca ve Tibetçe arasında da iki yönlü çeviri yapabiliyor.
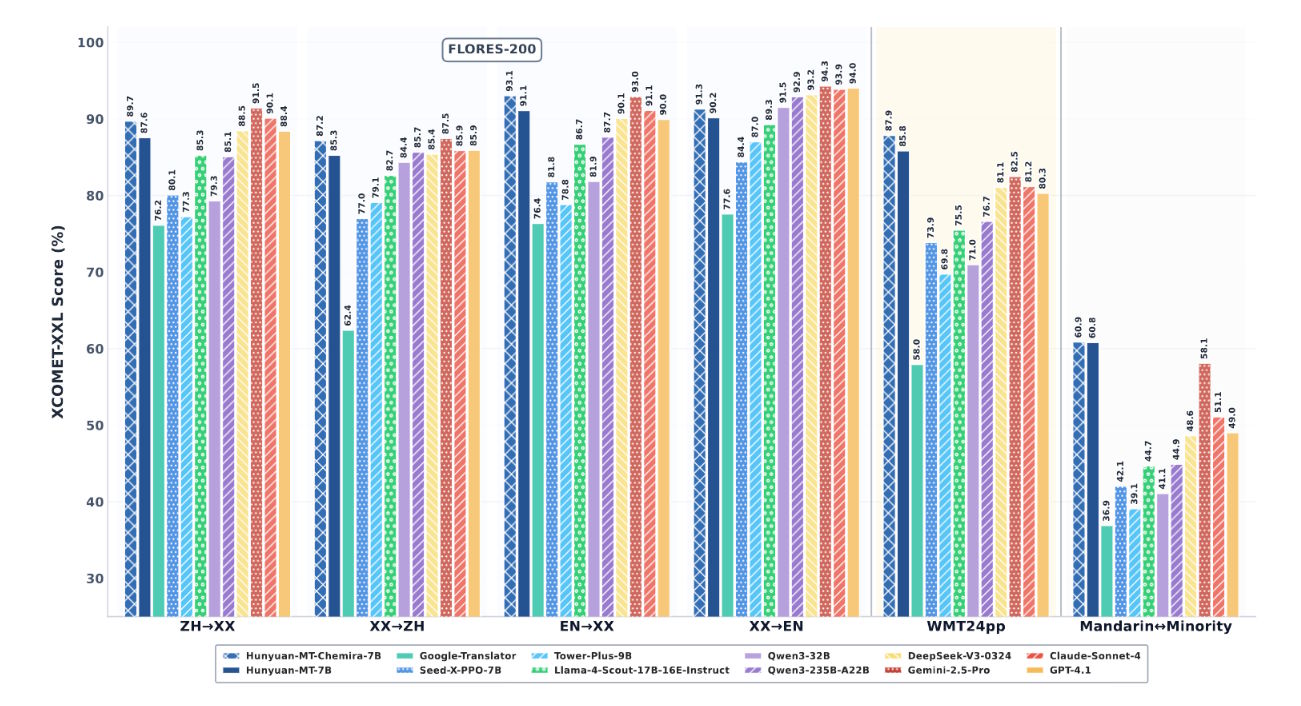
7B Parametreli Modeller Daha Büyük Rakipleri Geride Bıraktı
Tencent’in teknik raporu, Hunyuan modellerinin doğrudan karşılaştırmalarda yerleşik sistemleri geçtiğini ortaya koydu. Google Translate’e kıyasla sonuçlar, dile ve ölçütlere bağlı olarak yüzde 15 ila 65 arasında gelişme gösterdi. GPT-4.1, Claude 4 Sonnet ve Gemini 2.5 Pro gibi özel YZ sistemleri de testlerin çoğunda geri planda kaldı.
7 milyar parametreye sahip modeller, kendi sınıfındaki birçok temel modele kıyasla daha küçük boyutta. Böylelikle daha az hesaplama gücü gerektiriyor ve daha zayıf donanımlarda çalışabiliyor. Kıyaslamalar, performansta daha büyük sistemlerle eşleştiğini hatta çoğu durumda onları geçtiğini gösterdi. Özellikle 72 milyar parametreye kadar çıkan Tower Plus serisini yüzde 10 ila 58 oranında geride bıraktı.
Başlıca dil çiftleriyle yapılan karşılaştırmalarda da her iki Hunyuan modeli net üstünlük gösterdi. Gemini 2.5 Pro’ya karşı yüzde 4,7 daha yüksek skor aldı. Özel çeviri modellerine karşı testlerde ise gelişme oranı yüzde 55 ile 110 arasında değişti.
Modeller Hugging Face üzerinde açık kaynaklı olarak yayımlandı ve Tencent ayrıca kaynak kodunu GitHub üzerinden de paylaştı.
Eğitim Süreci Gelişmiş Sonrası Yöntemlerle Güçlendirildi
Tencent, beş aşamalı bir eğitim süreci uyguladı: Önce genel metinler üzerinde eğitim yapıldı, ardından çeviri odaklı veriyle ince ayar gerçekleştirildi. Sonrasında örnek çeviriler üzerinde denetimli öğrenme, ödül sinyalleriyle pekiştirmeli öğrenme ve son olarak “weak-to-strong” adı verilen bir pekiştirmeli öğrenme adımı izlendi.
Eğitim verisi, yalnızca azınlık dilleri için 1,3 trilyon token içerdi. Toplamda 112 dil ve lehçeyi kapsayan bu veri, bilgi değeri, özgünlük ve yazım tarzı açısından özel bir değerlendirme sisteminden geçirildi.
Chimera modeli, farklı sistemlerden gelen birden fazla çeviri önerisini birleştirerek daha güçlü sonuçlar üretmek üzere tasarlandı. Tencent, bu yöntemin standart test performansını ortalama yüzde 2,3 oranında artırdığını belirtiyor.
Bu arada Google da yakın zamanda çeviri hizmeti için yeni YZ özelliklerini duyurdu. Özellikler arasında canlı konuşmalar için gerçek zamanlı çeviri ve kişiselleştirilmiş dil öğrenme modu yer alıyor. Google, özelliklerin Gemini modellerinin gelişmiş akıl yürütme ve çoklu modalite yetenekleriyle desteklendiğini açıkladı.
Kaynak: https://the-decoder.com/tencent-open-sources-two-high-performing-translation-models/
İlginizi Çekebilir
Kategoriler
Kurumsal
En Önce Sizin Haberiniz Olsun!
Bu Websitesi'nin Dönüşmleri
Pinetent Digital AgencyTarafından Yapılmaktadır. ©2024 Nuvem Tüm Hakları Saklıdır.