Yapay Zeka Uygulamaları
29/9/2025
OpenAI, GPT-5’i İnsanlarla Kıyasladı: 44 Meslekte Test Edildi

OpenAI, perşembe günü yayımladığı yeni bir kıyaslama testiyle modellerinin insan profesyonellerle karşılaştırıldığında nasıl performans gösterdiğini açıkladı. GDPval adı verilen bu test, şirketin kurucu misyonunda yer alan genel yapay zeka (AGI) geliştirme hedefine giden yolda, ekonomik açıdan değerli işlerde YZ’nin insanları geride bırakmaya ne kadar yaklaştığını anlamayı amaçlıyor.
Şirketin açıklamasına göre, GPT-5 modeli ve Anthropic’in Claude Opus 4.1 modeli “sektör uzmanlarının ürettiği iş kalitesine yaklaşmaya başladı” ancak OpenAI, bunun insanları işlerinden hemen edecek bir gelişme olmadığını vurguluyor. Bazı CEO’ların birkaç yıl içinde YZ’nin insanları işlerinden çıkaracağına yönelik tahminlerine rağmen, GDPval’in şu an yalnızca gerçek işlerin sınırlı bir bölümünü kapsadığı belirtiliyor. Yine de söz konusu ölçüm, ilerlemenin izlenmesi açısından kritik görülüyor.
GDPval, Amerika’nın gayrisafi yurt içi hasılasına en çok katkıda bulunan dokuz endüstriyi temel alıyor. Sağlık, finans, üretim ve hükümet gibi alanlarda toplam 44 meslek test edildi. Yazılım mühendislerinden hemşirelere, gazetecilerden yatırım bankacılarına kadar geniş bir yelpaze değerlendirildi. İlk versiyon olan GDPval-v0’da, deneyimli profesyonellerden YZ tarafından üretilen raporlarla meslektaşlarının raporlarını karşılaştırmaları ve hangisinin daha iyi olduğuna karar vermeleri istendi. Örneğin yatırım bankacılarından son kilometre teslimat sektörü için rakip analizleri hazırlamaları ve bunları YZ’nin ürettikleriyle kıyaslamaları talep edildi. Ardından YZ’nin “kazanma oranı” tüm meslekler genelinde ortalama olarak hesaplandı.
Geliştirilmiş sürüm olan GPT-5-high, sektör uzmanlarından daha iyi ya da en az onlar kadar iyi bulunduğu durumlarda %40,6 oranına ulaştı. Karşılaştırmada yer alan Claude Opus 4.1 ise %49 oranıyla daha yüksek bir sonuç elde etti. OpenAI, Claude’un bu başarıyı performansından çok “göze hoş gelen grafikler” üretme eğilimine borçlu olabileceğini ifade ediyor.
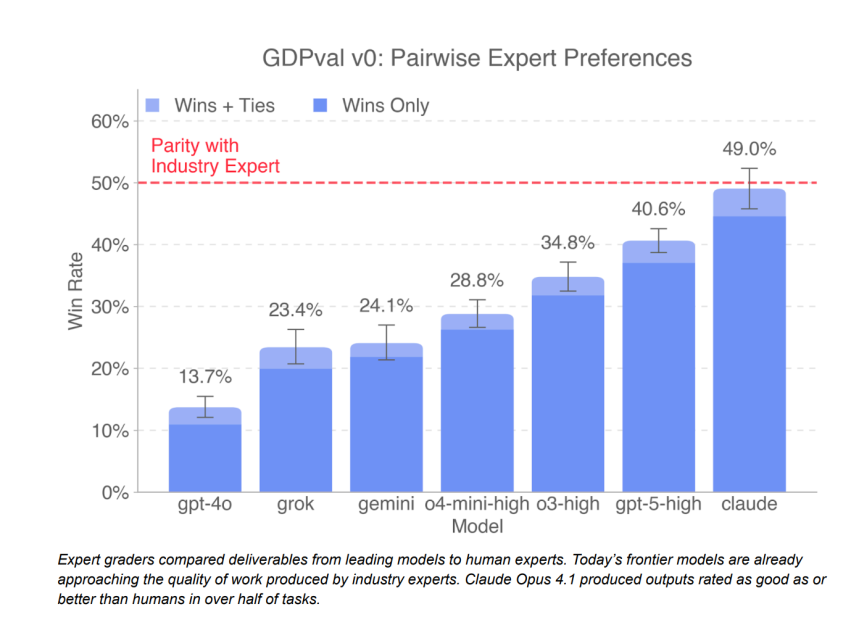
OpenAI, GDPval-v0’ın yalnızca araştırma raporlarına odaklandığını, gerçek hayatta profesyonellerin çok daha çeşitli görevler üstlendiğini kabul ediyor. Şirket, daha fazla endüstri ve etkileşimli iş akışlarını kapsayan daha kapsamlı testler geliştirmeyi planlıyor. Buna rağmen ilerlemenin dikkat çekici olduğu belirtiliyor. OpenAI baş ekonomisti Dr. Aaron Chatterji, TechCrunch’a verdiği röportajda şunları söyledi:
“Model bazı işlerde iyi bir seviyeye geldikçe, o görevlerde çalışan insanlar işleri YZ’ye devredip daha anlamlı ve potansiyel olarak daha yüksek değerli işlere odaklanabilir.”
OpenAI’nin değerlendirme ekibi lideri Tejal Patwardhan ise ilerleme hızını umut verici bulduğunu ifade etti. Yaklaşık 15 ay önce yayımlanan GPT-4o yalnızca %13,7 oranında (insanlara karşı kazanma ve berabere kalma) başarı göstermişti. Bugün GPT-5’in ulaştığı oran bunun yaklaşık üç katı. Patwardhan, gelişim trendinin sürmesini beklediğini dile getirdi.
YZ araştırmalarında hâlihazırda AIME 2025 (rekabetçi matematik problemleri) ve GPQA Diamond (doktora seviyesinde bilim soruları) gibi popüler testler kullanılıyor fakat birçok model testlerde doygunluğa ulaştığından, araştırmacılar gerçek dünyadaki iş yetkinliklerini ölçebilecek yeni yöntemlerin gerekliliğini vurguluyor. OpenAI’nin geliştirdiği GDPval’in bu noktada giderek daha önemli bir rol üstlenebileceği düşünülüyor. Yine de şirket, modellerinin insanlardan daha iyi performans gösterdiğini kesin biçimde ortaya koymak için daha geniş kapsamlı versiyonlara ihtiyaç olduğunu kabul ediyor.
Kaynak: https://techcrunch.com/2025/09/25/openai-says-gpt-5-stacks-up-to-humans-in-a-wide-range-of-jobs/
İlginizi Çekebilir
Kategoriler
Kurumsal
En Önce Sizin Haberiniz Olsun!
Bu Websitesi'nin Dönüşmleri
Pinetent Digital AgencyTarafından Yapılmaktadır. ©2024 Nuvem Tüm Hakları Saklıdır.