Yapay Zeka Uygulamaları
29/8/2025
Bilim İnsanları İnsan Beyninden Esinlenen Yeni Bir Yapay Zeka Geliştirdi: Akıl Yürütme Testlerinde ChatGPT Gibi LLM’leri Geride Bıraktı

Bilim insanları, mevcut büyük dil modellerinden (LLM) farklı bir şekilde akıl yürütebilen yeni bir yapay zeka modeli geliştirdi. Hiyerarşik Akıl Yürütme Modeli (HRM) adı verilen sistem, özellikle akıl yürütme gerektiren testlerde ChatGPT gibi en gelişmiş LLM’lerden çok daha iyi sonuçlar elde etti.
Yeni model, insan beynindeki hiyerarşik ve çoklu zaman ölçekli bilgi işleme yaklaşımından ilham alıyor. İnsan beyninde farklı bölgeler bilgiyi milisaniyelerden dakikalara kadar değişen sürelerde işler ve bütünleştirir. Singapur merkezli yapay zeka şirketi Sapient’in bilim insanları, HRM’nin daha verimli çalışabildiğini ve çok daha az parametre ile daha iyi sonuç verdiğini belirtiyor.
Araştırmaya göre HRM, yalnızca 27 milyon parametre kullanıyor ve 1.000 eğitim örneği ile çalıştırıldı. Karşılaştırmak gerekirse, en gelişmiş LLM’ler milyarlarca hatta trilyonlarca parametreye sahip. Henüz resmi olarak açıklanmasa da tahminler, kısa süre önce tanıtılan GPT-5’in 3 ile 5 trilyon parametre arasında olduğunu gösteriyor.
Yapay Zeka için Yeni Bir Düşünme Yöntemi
Araştırmacılar, HRM’yi ARC-AGI benchmark testinde değerlendirdi. Test, modellerin yapay genel zekaya (AGI) ne kadar yakın olduğunu ölçmeyi amaçlıyor ve zorluğuyla biliniyor. Çalışmaya göre HRM, dikkat çekici başarılar elde etti.
- ARC-AGI-1 testinde HRM %40,3 skor aldı. Karşılaştırıldığında OpenAI’nin o3-mini-high modeli %34,5, Anthropic’in Claude 3.7’si %21,2 ve Deepseek R1 %15,8 seviyesinde kaldı.
- Daha zor olan ARC-AGI-2 testinde HRM %5 başarı elde ederken, o3-mini-high %3, Deepseek R1 %1,3 ve Claude 3.7 %0,9 oranında kaldı.
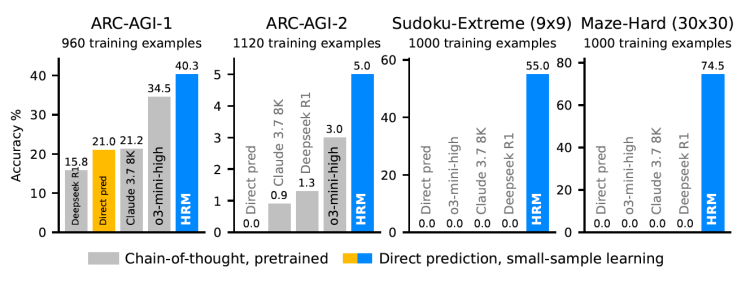
Çoğu gelişmiş LLM, zincirleme düşünme (Chain-of-Thought, CoT) yöntemini kullanıyor. Bu yaklaşım, karmaşık problemleri çok daha basit ara adımlara bölerek doğal dil üzerinden çözüyor. İnsan düşünce sürecine benzer şekilde, büyük problemleri parçalayarak ilerliyor fakat Sapient bilim insanları çalışmada, CoT yaklaşımının ciddi zayıflıkları olduğunu belirtti: “kırılgan görev parçalama, kapsamlı veri gereksinimleri ve yüksek gecikme.”
HRM ise ara adımlar için açık bir yönlendirme olmadan, yalnızca iki modül aracılığıyla tek seferlik ileri besleme (forward pass) ile sıralı akıl yürütme görevlerini yerine getiriyor. Üst düzey modül soyut ve yavaş planlamadan sorumluyken, alt düzey modül hızlı ve ayrıntılı hesaplamaları yürütüyor. Bu yapı, insan beyninde farklı bölgelerin bilgiyi işleme biçimine benzetiliyor.
HRM, iteratif iyileştirme (iterative refinement) yöntemini kullanıyor. Söz konusu teknik, başlangıçtaki bir çözümü tekrar tekrar gözden geçirerek daha doğru hale getiriyor. Sistem, kısa “düşünme” döngüleriyle ilerliyor; her döngüde sürecin devam edip etmeyeceğine veya mevcut çözümün “nihai” yanıt olarak sunulup sunulmayacağına karar veriyor.
Böylelikle HRM, karmaşık Sudoku bulmacalarında neredeyse kusursuz sonuçlar elde etti. Geleneksel LLM’lerin başaramadığı bu alanda HRM öne çıkarken, ayrıca labirentlerde en uygun yolun bulunmasında da üstün performans gösterdi.
Çalışmanın Yankıları
Araştırma henüz hakem değerlendirmesinden geçmedi, ancak HRM’nin açık kaynak olarak GitHub’da paylaşılmasının ardından ARC-AGI benchmark organizatörleri sonuçları kendileri yeniden üretmeye çalıştı. Sayılar doğrulandı, ancak beklenmedik bir bulguya rastlandı. Organizatörlerin blog yazısında belirttiğine göre, “hiyerarşik mimarinin performansa etkisi minimal düzeydeydi — asıl farkı yaratan unsur, eğitim sırasında belgelenmemiş bir iyileştirme süreciydi.”
Sonuç olarak HRM, insan beyninin bilgi işleme yaklaşımından esinlenen farklı bir yapay zeka yöntemiyle dikkat çekici başarılar ortaya koyarken, modelin hangi tekniklerle bu sonuçlara ulaştığı tartışma konusu olmaya devam ediyor.
İlginizi Çekebilir
Kategoriler
Kurumsal
En Önce Sizin Haberiniz Olsun!
Bu Websitesi'nin Dönüşmleri
Pinetent Digital AgencyTarafından Yapılmaktadır. ©2024 Nuvem Tüm Hakları Saklıdır.