Yapay Zeka
9/12/2025
Google, LLM'lere Uzun Süreli Bellek Kazandırmak için Titans Mimarisini Tanıttı

Birçok uzman, LLM'ler (Büyük Dil Modelleri) için "her etkileşimin esasen sıfırdan başladığı uzun süreli bellek eksikliğinin" modellerin büyük ölçekli dağıtımı önündeki en büyük engel olduğunu belirtirken, Google durumu değiştirmeye yardımcı olacak bir yol geliştirdi.
Yayımlanan iki yeni araştırma makalesinde Google yeni bir mimari olan Titans'ı ve yapay zeka modellerinin bağlamı ve belleği ele alış biçiminde temel bir değişimi temsil eden teorik çerçeve MIRAS'ı tanıttı. Teknoloji devi tarafından duyurulan atılım, veriler akarken modellerin gerçek zamanlı olarak öğrenmesini ve uyum sağlamasını mümkün kılarken, yinelemeli sinir ağlarının (RNN) işlem hızını transformerların doğruluğuyla birleştiriyor.
Bağlam Sorunu
Geleneksel transformer modelleri, yeni bilgileri işlerken modellerin daha önceki girdilere referans vermesini sağlayan dikkat (attention) mekanizmaları aracılığıyla yapay zekada bir devrim yarattı ancak mevcut yaklaşım önemli bir sınırlamayla birlikte geliyor: Hesaplama maliyetleri dizi uzunluğuyla birlikte ciddi oranda artıyor ve tam dokümanlar veya genomik diziler gibi son derece uzun bağlamların işlenmesini pratik olmaktan çıkarıyor.
Araştırma topluluğu doğrusal yinelemeli sinir ağları ve Mamba-2 gibi durum uzayı modelleri (state space models) gibi alternatifleri araştırmış olsa da, bahsi geçen çözümler bağlamı sabit boyutlu temsiller halinde sıkıştırıyor ve çok uzun dizilerde bulunan zengin bilgileri yakalamakta zorlanıyor.
Titans Nasıl Çalışır?
Titans, Google'ın "test zamanı ezberleme" (test-time memorization) olarak adlandırdığı, yani model aktif olarak çalışırken çevrimdışı yeniden eğitime gerek duymadan parametrelerini güncelleyerek uzun süreli belleği koruma yeteneği sayesinde zorluğun üstesinden geliyor.
Mimari, derin bir sinir ağı, özellikle de çok katmanlı bir algılayıcı (MLP) olarak işlev gören sinirsel bir uzun süreli bellek modülü sunuyor. Bellek için sabit boyutlu vektörler veya matrisler kullanan geleneksel RNN'lerin aksine, geliştirilen yöntem önemli ölçüde daha yüksek ifade gücü sağlayarak modelin önemli bağlamı kaybetmeden büyük hacimli bilgileri özetlemesine olanak tanıyor.
Temel yenilik, Google araştırmacılarının "sürpriz metriği" (surprise metric) olarak adlandırdığı kavramda yatıyor. Rutin olayları kolayca unuttuğumuz ancak beklenmedik olanları hatırladığımız insan psikolojisinden ilham alan Titans, yeni bilgilerin modelin halihazırda hatırladıklarından ne zaman önemli ölçüde farklılaştığını tespit etmek için dahili bir hata sinyali kullanıyor.
Bağlam içinde beklenen bir kelimeyle karşılaşmak gibi sürpriz seviyesinin düşük olduğu durumlarda, model bilgiyi kalıcı olarak depolamayı atlayabiliyor. Bir finansal raporda anormal bir veri noktasıyla karşılaşmak gibi sürpriz yüksek olduğunda ise model, veriyi uzun süreli belleğinde kalıcı olarak saklamaya öncelik veriyor.
Google mekanizmayı iki kritik unsurla geliştirdi: Bireysel belirteçler (token) şaşırtıcı olmasa bile modelin ilgili sonraki bilgileri yakalamasını sağlayan momentum ve son derece uzun dizilerle uğraşırken belleğin sınırlı kapasitesini yönetmek için bir "unutma kapısı" görevi gören uyarlanabilir ağırlık azaltma (adaptive weight decay).
MIRAS Çerçevesi
MIRAS, söz konusu yaklaşımları anlamak ve genelleştirmek için gerekli teorik temeli sağlıyor. Farklı yapay zeka mimarilerini ayrı sistemler olarak görmek yerine MIRAS, onları aynı temel sorunu çözmenin, yani temel kavramları kaybetmeden yeni bilgileri eski anılarla verimli bir şekilde birleştirmenin farklı yöntemleri olarak ele alıyor.
Çerçeve, dizi modellerini dört temel tasarım seçimi üzerinden tanımlıyor: Bellek mimarisi, dikkat yanlılığı (attentional bias), tutma kapısı (retention gate) ve bellek algoritması. Önemli bir detay olarak MIRAS, mevcut hemen hemen tüm dizi modellerinin dayandığı ortalama kare hatası (mean squared error) paradigmasının ötesine geçerek, yeni mimariler yaratmak için daha zengin bir tasarım alanı açıyor.
Google, MIRAS'ı kullanarak dikkat mekanizmasız (attention-free) üç model varyantı oluşturdu: Aykırı değerlere karşı daha sağlam olan YAAD; daha kararlı uzun süreli bellek için karmaşık matematiksel cezaları araştıran MONETA ve belleğini katı bir olasılık haritası gibi davranmaya zorlayarak optimum bellek kararlılığına ulaşan MEMORA.
Performans Sonuçları
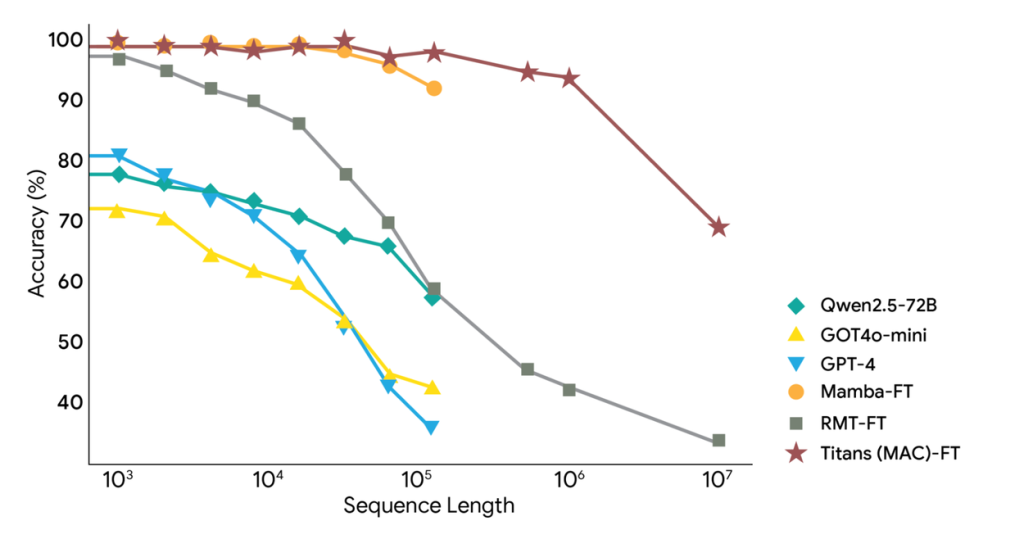
Google'ın testleri birden fazla kıyaslamada etkileyici sonuçlar gösteriyor. C4 ve WikiText gibi standart veri setlerini kullanan dil modelleme görevlerinde Titans ve MIRAS varyantları, Transformer++, Mamba-2 ve Gated DeltaNet dahil olmak üzere önde gelen mimarilere kıyasla tutarlı bir şekilde daha yüksek doğruluk sergiledi.

En belirgin avantaj, aşırı uzun bağlam senaryolarında ortaya çıkıyor. Son derece uzun belgelere dağılmış gerçekler arasında akıl yürütmeyi gerektiren BABILong kıyaslamasında Titans, önemli ölçüde daha az parametreye sahip olmasına rağmen GPT-4 dahil tüm temel modellerden daha iyi performans gösterdi. Mimari, 2 milyon belirteçten (token) daha büyük bağlam pencerelerine etkili bir şekilde ölçeklenebilme yeteneğini kanıtladı.
Ablasyon çalışmaları, bellek mimarisinin derinliğinin çok önemli olduğunu doğruladı; daha derin bellek modülleri, dizi uzunluğu önemli ölçüde arttığında bile sürekli olarak daha iyi performans sağlıyor ve bunu koruyor.
Yapay Zeka Dağıtımı için Çıkarımlar
Titans ve MIRAS'ın tanıtımı, yapay zeka dağıtımındaki en kalıcı zorluklardan birini çözmeye yönelik önemli bir adımı işaret ediyor. Her şeyi statik durumlara sıkıştırmak yerine veriler akarken modellerin aktif olarak öğrenmesini ve temel bilgilerini güncellemesini sağlayan yaklaşımlar, uzun bağlam anlayışı gerektiren alanlarda yeni uygulamaların önünü açabilir.
Google, mimarinin çok yönlülüğünü metnin ötesinde de doğruladı ve Titans'ı genomik modelleme ve zaman serisi tahminlerinde başarıyla test etti. Modeller, verimli, paralelleştirilebilir eğitim ve hızlı doğrusal çıkarım hızlarını koruyarak onları gerçek dünya dağıtımı için pratik hale getiriyor.
Kuruluşlar giderek artan bir şekilde karmaşık, uzun süreli etkileşimleri ele alabilen ve uzun oturumlar boyunca bağlamı koruyabilen yapay zeka sistemlerini devreye almaya çalıştıkça, RNN verimliliğini transformer düzeyinde ifade gücüyle birleştiren Titans gibi mimariler, büyük dil modellerinin mevcut sınırlamalarının ötesine geçmek için hayati önem taşıyabilir.
Kaynak: https://officechai.com/ai/google-introduces-titans-architecture-to-give-llms-long-term-memory/
İlginizi Çekebilir
Kategoriler
Kurumsal
En Önce Sizin Haberiniz Olsun!
Bu Websitesi'nin Dönüşmleri
Pinetent Digital AgencyTarafından Yapılmaktadır. ©2024 Nuvem Tüm Hakları Saklıdır.